ChatGPT o4 に、動画をアップロードして、文字起こしをしようとしたら
pythonで、行うようにと、ソースプログラムを表示してくれたのでやってみた
早速、Ubuntu 24.04のPCでやってみよう
まず、pythonなので、仮想空間を作る
python3 -V
Python 3.12.3
バージョンは 3.12.3
仮想空間を作るために
python3 -m venv voice
source voice/bin/activate
bash: voice/bin/activate: そのようなファイルやディレクトリはありません
メッセージをみたら、エラーを出していた
apt install python3.12-venv
インストールが必要
sudo apt install python3.12-venv
再度
python3 -m venv voice
source voice/bin/activate
こんどは、入れた
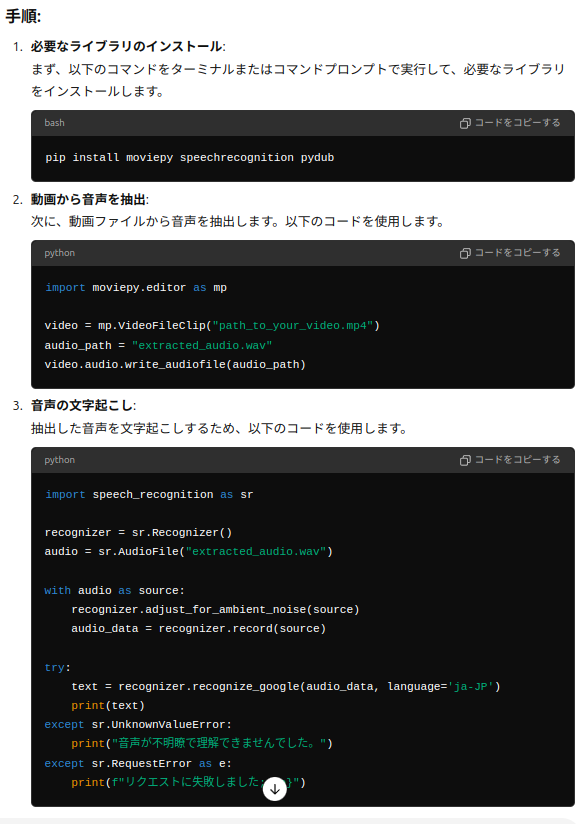
GPTが教えてくれた、コマンドで
pip install moviepy speechrecognition pydub
Collecting moviepy
で、必要なライブラリーをインストール
プログラムをmoji.pyで作っておいて
python3 moji.py
で、実行
エラーを表示、mp3は、だめで、wavとのこと
Audacityを使って、wavに変換
実行したら、時間がかかったが、画面に表示した
python3 moji.py > kekka.txt
で、ファイルに落ちた
案外精度はよさそうである
プログラムは、以下となっている
import speech_recognition as sr
recognizer = sr.Recognizer()
audio = sr.AudioFile(“extracted_audio.wav”)
with audio as source:
recognizer.adjust_for_ambient_noise(source)
audio_data = recognizer.record(source)
try:
text = recognizer.recognize_google(audio_data, language=’ja-JP’)
print(text)
except sr.UnknownValueError:
print(“音声が不明瞭で理解できませんでした。”)
except sr.RequestError as e:
print(f”リクエストに失敗しました; {e}”)
活用していってみよう